
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety

All models are wrong, but some are useful
- George E. P. Box
Has grocery shopping ever been a mildly traumatic experience for you? It certainly has for me. Nothing quite matches the feeling of entering the breakfast aisle with a very specific ask: grab this kind of cereal, only to find an assortment of ten different sub-kinds that seem to fit your criteria - each offering something just different enough to make you wonder if purchasing it will have you making the trek back to the store in twenty minutes.
Selecting an LLM often feels like a high-stakes version of the same game. Select a model, utilize expensive resources tuning it, spend precious hours testing it, only to find that I didn't take enough time to read the ingredients and I accidentally brought home the cereal with nuts. Only this time, rather than a short drive to the grocery store you're left with starting from square one with disillusioned colleagues and/or customers and a drooping confidence that you'll know what to look for next time.
We all see the transformative impact LLMs are having across a variety of industries, but how do we take the plunge into this exciting space while mitigating the risks that come with it? How can we determine which of the dozens of available options are the right fit? How do we ensure that we're getting the output from my model that we expect? How do we know that the chatbot we build won't rage at my customer, or make promises to them we can't keep?
What LLM do we choose, and how do we choose it?
My early ventures in this space were limited primarily to code generation. I'll never forget the day ChatGPT was released to the public. My wife had been repeatedly kicking my butt in games of Farkle, and like any competitive nerd with a background in statistics I wondered if I could build myself an app that would recommend how many dice to roll given the context. Not wanting to start completely from scratch, I fed a description of the problem to my new handy assistant, was delivered functioning code that got me a good chunk of the way there, had my mind blown at what the future might look like, and had to implement a "no-phones" Farkle house-rule.
Choosing a model for that purpose is fairly straightforward - jam the request into whatever API you can get your hands on and select the one that best solves the problem. But what if you're thinking beyond pet projects and on to more specific, production-proof use cases that come with security, fine-tuning, pricing, and legitimacy concerns?
The good news is, model selection isn't a new problem, as data researchers have been grappling with this issue in the realm of traditional machine learning for decades. However, the advent of LLMs has introduced a new paradigm, rendering the conventional techniques for model selection inadequate. This shift, while daunting, also presents an exciting opportunity to redefine our approach to model selection. Through this post, I hope to guide you through the metrics that can help you navigate this new landscape and choose the model that is right for your endeavor.
In traditional machine learning, we have a set of well-established metrics that guide our model selection. Accuracy, precision, recall, mean squared error - these are the yardsticks by which we measure a model's performance. But when it comes to LLMs, these metrics fall short. They fail to capture the nuanced capabilities of these models, which are designed to understand context and generate natural language.
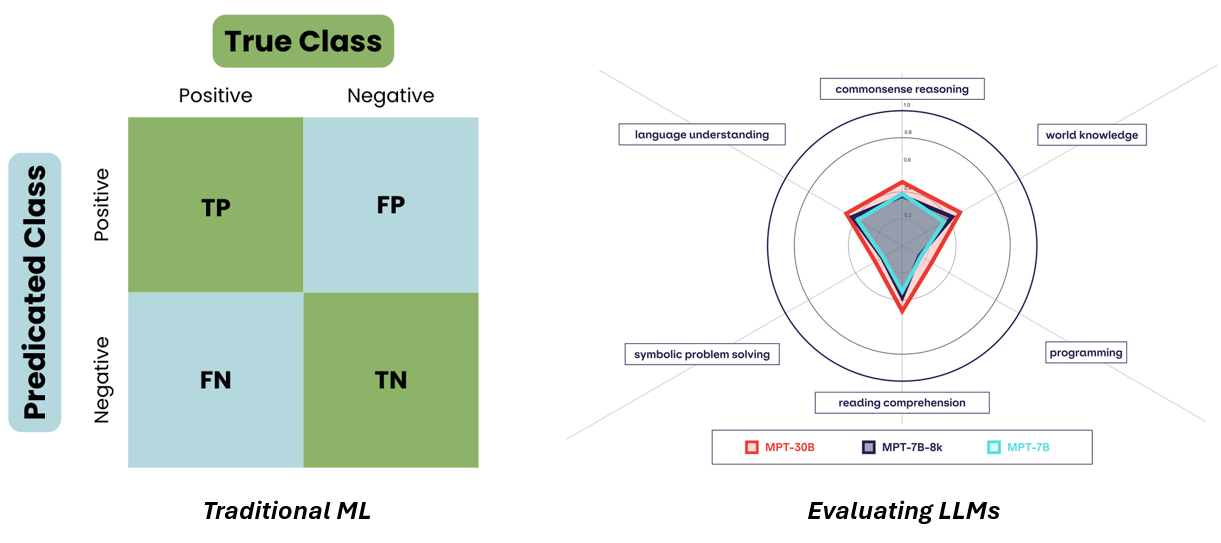
Furthermore, the concept of "ground truth" takes on a different meaning in the LLM space compared to traditional machine-learning. These generative models don't adhere to any definitive, binary notion of a target variable. Instead, they operate in a realm where the output isn't constrained to a single correct answer but spans a spectrum of possibilities.
This departure from a binary ground truth significantly alters the relevance and interpretation of metrics like those that have ruled the day in the past. Accuracy, precision, recall, ROC - take your pick of favorite scikit-learn metrics - all depend upon such a target variable. However, for LLMs, the notion of correctness is more nuanced. Their outputs involve generating text that is contextually appropriate, coherent, and semantically meaningful rather than simply matching predefined labels.
So, how do we evaluate these models? How do we navigate this new landscape? The answer lies in redefining our approach to model selection. We need to move beyond traditional metrics and embrace new strategies that can capture the unique capabilities of LLMs.
There are a few examples of approaches that move beyond static metrics to dynamic, interactive, and application-specific benchmarks.
One such approach is HumanEval. Rather than evaluating a model's ability to predict outcomes, this approach assesses an LLM's ability to understand and generate functional code. A traditional ML scorer might compare the difference between the text in generated code and an actual solution, but each problem may have dozens of solutions, thereby making this kind of evaluation quite impractical. To address this, HumanEval provides a model with a set of 164 handwritten programming problems assessing language comprehension, algorithms, and simple mathematics, and grades the output of the model based on whether or not the application of the provided code solves the given problem.
Additionally, there's Hellaswag, which uses Adversarial Filtering to generate multiple-choice questions about videos that are trivial for humans, but especially hard even for state-of-the-art models. These tests allow for the evaluation of a given model's ability to apply common-sense reasoning in a given context.

TruthfulQA is yet another evaluation protocol that measures the truthfulness of a model's response, and asks questions that are designed in such a way that humans might give incorrect answers due to false beliefs or misunderstandings. To pass this test, models need to be careful about simply regurgitating human texts, as doing so might lead them to replicate the same misconceptions. This is particularly relevant for larger models, which are likely to be less truthful due to their larger data requirements and the greater chance of ingesting false but popular information.
Some approaches like the LMSYS Chatbot Arena forego the creation of a novel benchmark by putting the decision directly into the hands of users. A user can provide a prompt which is then fed to two random models. The user may then choose their favorite response and the competing models go up or down in ELO as a result. Others might even abstract away users by going with an LLM-as-a-Judge approach.
As you can see, in the world of LLMs, the traditional notion of accuracy morphs into something more nuanced. It's not just about predicting outcomes; it's about generating meaningful, contextually appropriate responses. Each model is designed for a specific task, and its prowess is gauged by its ability to excel at that task.
If you're looking ahead at the daunting journey of implementing an LLM-enabled project at your business you're likely wondering about various models - which ones can discern facts from myths? Which models reason well mathematically? Which models will better protect me from the embarrassment and delegitimization that comes as a result of a customer-facing product providing false information?
When it comes to applying LLMs in real-world scenarios, the required competencies can vary greatly. Some use cases require a general model with competence across a wide range of categories. Others might lean heavily in one area while having lesser needs in others, and will require a model with a more specific skillset.
At Rearc, we recognize the complexities involved in choosing and evaluating LLMs. Our team of experts is dedicated to providing tailored solutions to meet your unique needs, ensuring that you harness the full potential of language models without fear or hesitation.
Ready to unlock the full potential of LLMs for your business? Get in touch with us today to learn how we can help you harness the power of language models to drive innovation and success.
Contact us at ai@rearc.io to begin your journey with LLMs!
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!